Weekly Update (5/28/2021): Ava Labs Engineering

Development across the Avalanche ecosystem is growing rapidly, with new teams, applications, and assets being created every day. To keep the community up-to-speed on the work Ava Labs is doing to support these amazing efforts, we publish this weekly blog to recap our contributions to key technical areas.
This blog also provides information on how developers can get more involved in the Avalanche ecosystem, through programs like bug bounties, developer office hours, and career opportunities. Without further ado, here is this week’s engineering update:
Database Migration Recap
Last week, the code for the database migration was released as AvalancheGo@v1.4.5. Because that release was far and away the biggest item we worked on last week, I opted to summarize things in a short Twitter thread instead of on Medium. I think the folks on Discord summed up our expectation of a > 90% reduction in read IO best:
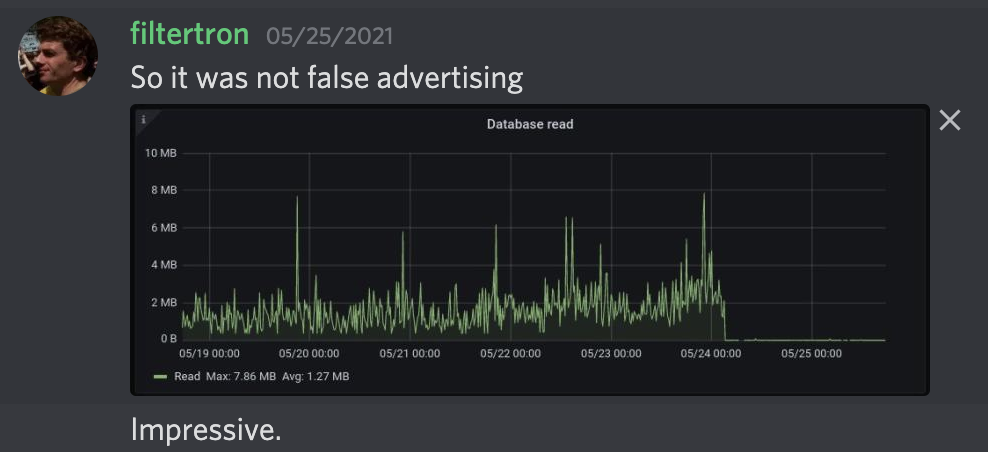
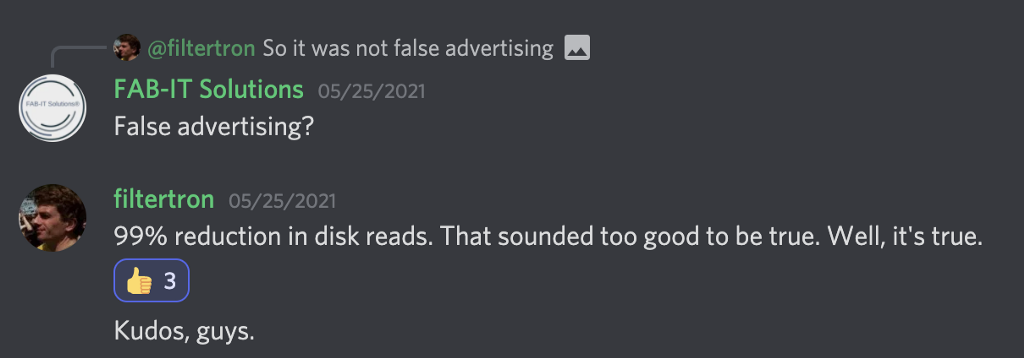
This week, we introduced a number of improvements and optimizations based on community feedback and recently released AvalancheGo@v1.4.7. If you haven’t migrated yet (you are still on version < v1.4.5), it is now easier than ever to do so with our new step-by-step instruction guide. You DO NOT need to upgrade from v1.4.4 to v1.4.5 before upgrading to v1.4.7 (the automated migration manager can go from v1.4.0-v1.4.4 directly to v1.4.7). For all the details around this upgrade and for answers to FAQs, you can check out the full upgrade guide.
Since the release of this code, many people reached out to me asking how we were able to achieve these large gains in DB efficiency. I worked with the Platform team to compile a summary of the three biggest changes:
Removed All Database Iteration from Block Processing
Previously, the current validator set was stored as a list sorted by the end times of the stakers and the pending validator set was stored as a list sorted by the start times of the stakers. When AddDelegatorTxs and RewardDelegatorTxs were verified, it required a complex analysis of the validator set. This caused AddDelegatorTxs and RewardDelegatorTxs to perform iterations over each of these databases, which resulted in a significant number of database reads.
Now, the validator set is cached in its object format, which avoids database reads while also avoiding repeated parsing of the data structure. To maintain the validator set over multiple processing blocks without a blowup in memory, the validator set is now managed as a Copy on Write data structure that is passed between blocks.
Added Additional Platformvm Caching
Previously, the platformvm had little to no caching implemented. The platformvm used to track block diffs using an implementation of the database interface. The database interface intentionally didn’t contain caching in order to avoid a large increase in memory utilization. This increase would have been non-trivial because the caching would have to be done on a per-layer basis, keeping duplicate values scattered throughout memory.
Now, there are two different implementations that manage the chain state. This first implementation lives on top of the database and caches parsed values. The second implementation tracks the diff between two chain states values. When a block is accepted, the diff is applied to the base chain state manager. This enables the efficient caching of parsed values while minimizing the memory footprint.
Grouped Related Values into Single Key-Value Pairs
Previously, related key-value pairs were stored separately. For example, a single validator would cause a transaction, a transaction status, an entry in the sorted validator set, and the node’s uptime to be tracked in the database.
By combining these values, we now store far fewer key-value pairs in the database and perform less database reads. Increasing the size of a key-value pair does increase the amount of time to read and write the value, however, this increase is significantly less than the improvement from reducing the number of reads and writes.
API Re-Architecture Progress
Yesterday, we rolled out our first round of API performance improvements and are now serving cached responses from a CDN 30% of the time:

Why should this matter to you? Well, the more responses we are able to cache the more the CDN can serve you directly without needing to relay your request to a node. Responses returned by the CDN tend to arrive in ~80% less time than responses served directly by an API node. So, anything that uses api.avax.network will appear dramatically faster without any changes on the client side.
For example, you can now fetch a block in ~50–60 ms from anywhere in the world:
curl --location \
--request POST 'https://api.avax.network/ext/bc/C/rpc' \
--header 'Content-Type: application/json' \
--data-raw '{
"jsonrpc": "2.0",
"method": "eth_getBlockByHash",
"params": [
"0x73e8bc7dc66c50714f5b5240a4d478db411355dac5e3ecf69335ccf3aa8a284b",
true
],
"id": 1
}'
Documentation and Tutorial Blast
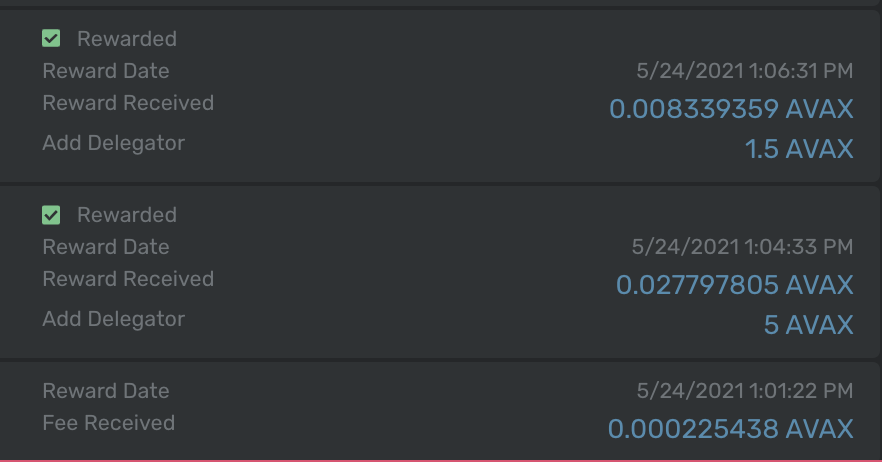
One of the great new features enabled by the database migration was better tracking of rewarded UTXOs. We added a new documentation page that shows how these can be accessed platform.getRewardUTXOs. For all historical validation periods, it is now possible to see exactly how much was rewarded.
Additionally, we completed multiple new tutorials for the C-Chain. We now have docs and tutorials for:
- Transferring an ANT on the C-Chain
- Getting the balance of an ANT on the C-Chain
- Forking Mainnet/Fuji state on the C-Chain for local smart contract development
- Verifying smart contracts on the C-Chain Explorer
- Creating ARC-20s
Everyday Updates
Each week there are many small but meaningful improvements made to the repos we maintain (usually based on feedback from the Avalanche community). Oftentimes they don’t warrant their own section but are still worth calling attention to. Here are this week’s “everyday” improvements:
- Wallet staking rewards now accessible in an address’s transaction history (using the new platform.getRewardUTXOs endpoint):
- AvalancheJS v3.5.0 was released (includes support for the new websocket endpoint for the X-Chain)
- Ortelius updated to use new Index API (all releases >= v1.4.5)
Office Hours
Over the last few weeks, the Ava Labs engineering team has been hosting focused office hours on Discord from 2–4 PM ET each Wednesday. Last week the Client Apps (Wallet, Ledger, Ortelius) team hosted office hours. This Wednesday, office hours will be hosted by the Platform (avalanchego, coreth) team.
If you can’t make the office hours, you can always reach out with questions on Discord or on Twitter.
Join Ava Labs
Ava Labs was founded by Cornell computer scientists who brought on talent from Wall Street to execute their vision. The company has received funding from Andreessen Horowitz, Initialized Capital, and Polychain Capital, with angel investments from Balaji Srinivasan and Naval Ravikant.
We are actively hiring for a number of key technical roles. To ensure we attract the best and brightest to join our team, we support hiring remote candidates from anywhere in the world. If the work we are doing interests you, we’d love to chat! You can apply here.
If you don’t know what role to apply for or want to bump your application to the top of the stack, you can take a short 25 minute technical assessment to demonstrate your skills. We’ll reach out promptly if you demonstrate the talent that would make you a great fit at Ava Labs.
![]()
Weekly Update (5/28/2021): Ava Labs Engineering was originally published in Avalanche on Medium, where people are continuing the conversation by highlighting and responding to this story.


